ontolo’s crawler/parser/indexer/whathaveyou might be the fastest that I know of in the marketing research space. Last I heard, moz’s machines crawl, parse and analyze at a rate of about 25,000,000 URLs per day. ontolo can do more than 400,000,000 per day and is limited not by the hardware or code, but by the maxed out gigabit network connection. And if you’ve seen any of the demos this week, you also know that ontolo collects orders of magnitude more data other research tools. And by the end of this, you’ll understand why that is.
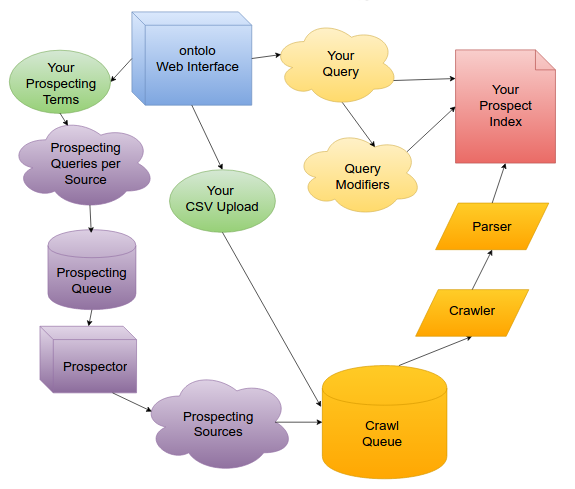
In the final post for the week, I’m going to walk you through how ontolo works, behind the scenes.
I’m writing this for you in plain language and a way that is easily understood, even if you don’t have a technical background. I’m also going to include technical details for folks who are interested, and those will be in sidebars with grey backgrounds.
So let’s get started.
C
Fundamentally, there are two parts to ontolo: Prospecting and Querying. Since you can’t query data that doesn’t exist, we’ll go through the ontolo prospect lifecycle, starting from a Prospecting Term or CSV Upload, all the way to a result from one of your queries.
Before I get into the process, there’s one critical piece here that’s important to understand, and that’s the programming language that ontolo is written in.
That language is: C.
Most operating systems that run the internet are written in C. And most of the popular programming languages are also written in C.
The reason that this is important is because C is fast. Very, very, very fast. It’s also dangerous. Where other programming languages have lots of things in place to keep you from Doing Bad Things, C doesn’t. C is a sawed-off shotgun, and if you don’t know how to fire it, it’s going to hurt. But if you do know how to fire it, it’ll get the job done very, very quickly.
Or, if you prefer a different kind of analogy, C is like riding a motorcycle, while other programming languages are like driving a truck. The motorcycle will be much faster, but offers far less protection in the event that Bad Things happen.
This extra protection that is offered by other programming languages comes at a cost of speed, resources (e.g. “gas”), etc.
To give a concrete example, the fastest I was ever able to get a crawler and very basic parser to run in PHP was at a rate of about 4,000,000 URLs a day. When I wrote one in Perl, I was barely able to hit 50,000,000 URLs per day analyzing far less than what ontolo now analyzes.
The reason these aren’t running at 400,000,000 URLs a day like ontolo is because they add in a lot of extra steps so that you can program things faster and have to worry about fewer things.
With C, you worry about everything. And in exchange, you can make things very, very fast.
I never thought I’d be a programmer, absolutely never a C programmer. But I trudged through the pain and agony and absurdity to learn it because if I was going to make this thing that was in my head, I was going to make in the absolute best, fastest way possible.
And, 20 months later, here we are.
Technical Note:For those who are interested, there is one C++ library being used for the search index, and everything else except the front-end is in C. Redis is used for queuing, and the MySQL connector is used in one spot, then XXHash64 is used for another piece. Every other piece of ontolo has been hand-written, from scratch, in pure C. I think you can C that I have fallen in love.
Prospecting
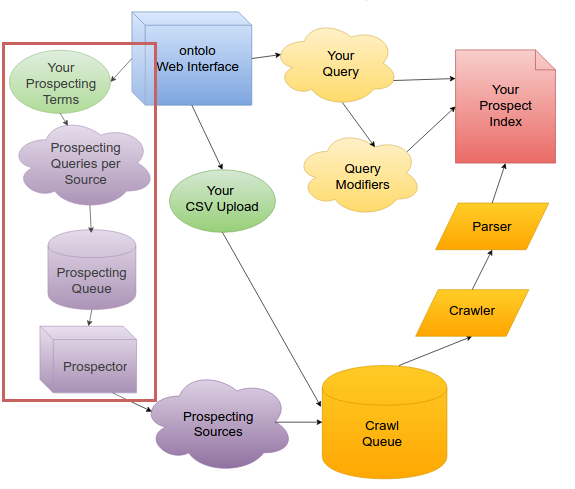
When you decide you want to find a new marketing prospect, you can either upload a URL list you might have from moz, AHrefs, Majestic, etc. or you can tell ontolo to find new prospects for you. I’ll come back to the upload option when discussing the crawler.
When you tell ontolo “I want to find blogs about rock climbing,” you just need to tell ontolo you want stuff about “rock climbing” when you’re on the Blogs tool.
ontolo takes your term, “rock climbing,” and then combines it with dozens of “prospecting templates” behind the scenes. So ontolo might expand that into “rock climbing blogs,” “rock climbing comments,” “rock climbing bloggers,” etc. In total, across all of the tools, ontolo has 765 different prospecting terms it uses, and this number continues to grow on an almost-weekly basis.
Once ontolo has expanded your Prospecting Term into a full group of terms, those then go into the Prospecting Queue, one per Prospect Source. (e.g. Bing)
Technical Note:The prospecting queue is currently a straightforward Redis instance with a queue per prospecting source. Redis announced this week the ability to build custom modules in C (this was only sort-of possible in Lua). And until that announcement, I’d begun working on my own rate-limited queuing system with some features that Redis doesn’t have. So we’ll see if I end up sticking with Redis, or continue working on a replacement.
Once a Prospecting Term is in the Prospecting Queue for a Prospect Source, there are dozens of machines – Prospectors – around the world that monitor the queues for each Prospect Source (e.g. Bing), then “pop” a prospecting term off the queue. That Prospector queries the Source, extracts the prospect URLs from the results, then adds those results to the Crawl Queue.
Rate Limiting and Prospecting
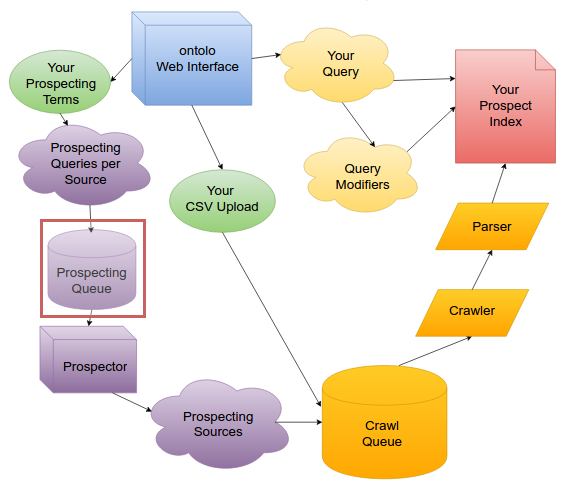
One thing that’s incredibly important to me is that we’re considerate of the technical resources from which we’re both Prospecting and Crawling. In other words, if we were to send 4,000 requests a second to Bing, we’d not only get blocked, but we’re also kind of assholes at that point. The same goes for the actual URLs we crawl, which I’ll get to in a bit.
Most folks “get around” being blocked by different sites by using a bunch of IPs or proxies so it’s more difficult to track that it’s actually one person making a bunch of requests. While ontolo does something similar, we also try to be very conservative and considerate in the rates with which we prospect from sites.
This is why the total number of Prospect Sources is important: more sources let us get you more prospects, faster, while still being considerate in terms of how frequently we visit a Prospecting Source each minute. In other words, if we decide “Across our entire prospector network, we’re going to only visit a site X time per minute,” more Prospecting Sources let us be equally considerate to all of our Prospecting Sources, but get you’re able to get more prospects, faster.
Uploading Prospects
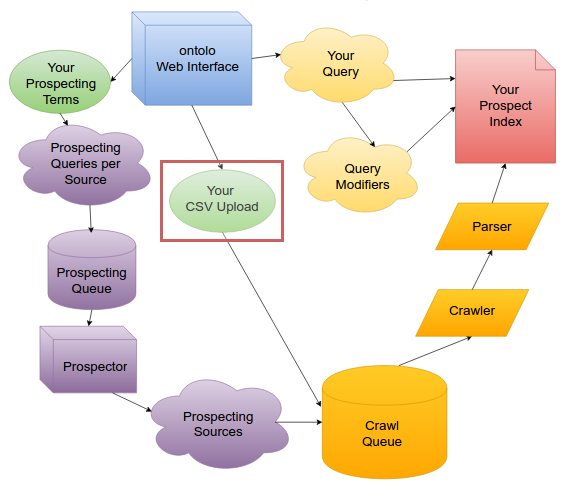
This is why uploading prospects is so much faster and can really begin to push the limits of the ontolo crawler’s network connection: There’s no waiting, the prospects are immediately added to the Crawl Queue.
Crawling
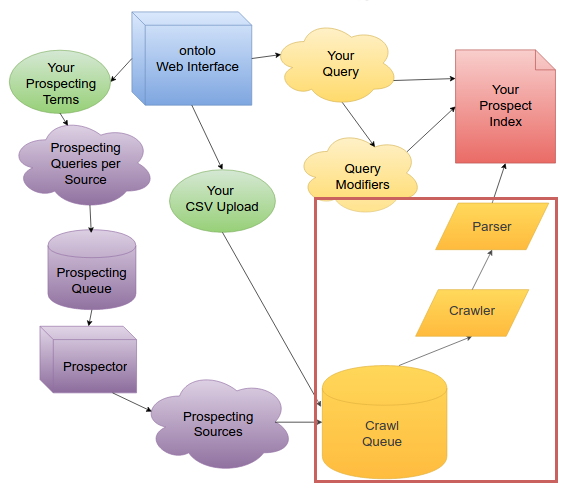
Similarly to how the Prospectors are constantly monitoring the queues for each Prospecting Source, the Crawler is constantly monitoring the Crawl Queue.
As soon as a new Prospect is added to the Crawl Queue, the Crawler immediately runs a rate-limiting check, then downloads that Prospect URL.
Rate Limiting the Crawler
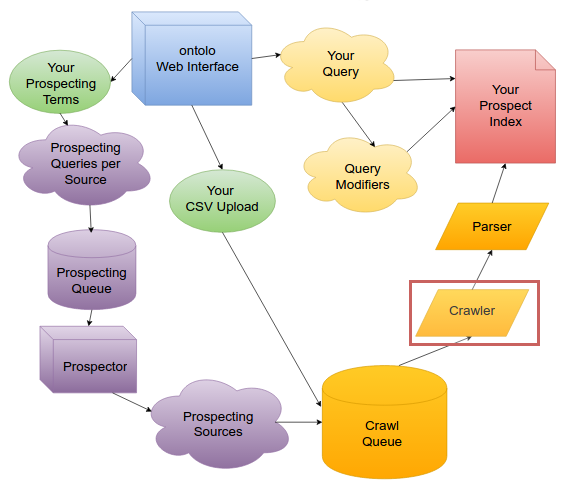
Right now, the Crawler is rate-limited in a very basic way: if a Prospect pulled from the Crawl Queue, and that site has been crawled in the previous 1 second, the prospect is eliminated. Forever.
It’s a pretty crude form of rate-limiting, and it actually leaves a lot of prospects uncrawled.
For that reason, the new rate-limited queue will likely be released in the next two weeks, *possibly* this weekend. And that queue will allow 32 different web pages per site to be in the queue.
Technical Note:It turns out, rate-limiting algorithms aren’t as straightforward as the idea itself, and there are a few completely-reasonable ways to do it. I ended up designing several different algorithms and data structures, but none seemed to be the sort of elegant solution I look for. Until it hit me the other day.
The new algorithm and structure will take less than 5mb of memory, will hold data for more than 16k hostnames, and will allow the queue to store up to 32 URLs per hostname. Obviously, all of that is tunable, and the 16k may need to be extended to 32k or 64k. But the point is that the data stays small, increasing the odds of it sitting more often in the CPU’s L3 cache. At the same time, we’ll begin rate limiting per two seconds, rather than one second.
Some of you might have noticed that I’ve mentioned that the rate is limited by hostname rather than IP. I might go into this decision at some point in another post, but the important point is this: rate limiting by IP is a better way to do so, all around, BUT, it jacks with another part of the crawl process enough that I’m putting that off until later, as a very different solution would be needed, and major pieces of code would need to be rewritten. The solution I mention in the previous paragraph is an easy drop-in to the existing process.
Once a prospect makes it through the rate limiter, it then goes through the process of being downloaded. Once it’s downloaded, it then goes to the Parser.
Technical Note:The download process, even here, sticks with the idea of only using external libraries when absolutely needed: DNS lookups are handed sending requests via UDP. The DNS results are then parsed by the crawler before sending the request to the hostname’s IP. This entire process of parsing DNS packets is handled, byte by byte, in the crawler, not via syscalls like gethostbyname() or getaddrinfo(), etc. This lets us much more efficiently create asynchronous DNS requests.
There is, however, an increase in the number of syscalls, as getaddrinfo() is only a single call, while a UDP request requires, at a minimum, calls for socket(), sendmsg(), read()/recv(), and close(). But, clearly, the benefit of async calls far outweighs the cost of the syscalls.
The Parser
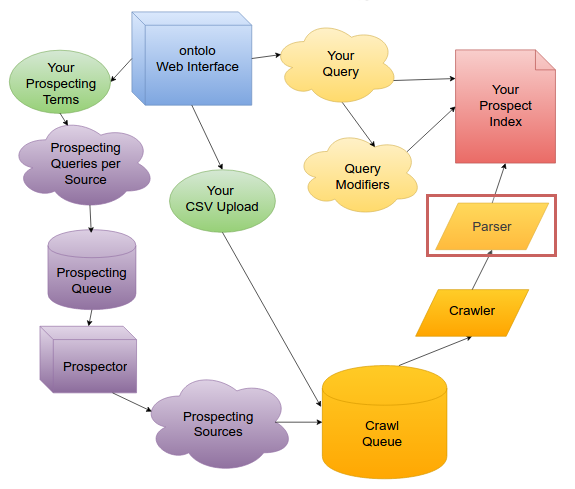
Once we’ve downloaded the HTML for the Prospect, it’s time to parse it.
If you’re unfamiliar with the idea of “parsing,” the simple idea is this: “On this we page, lets extract the Title and links.” Parsing is that process that pulls that information out of the HTML code.
But ontolo’s parser is far more detailed than that.
ontolo’s parser looks at a web page much more like a human does, rather than a computer. It’s able to “figure out” where the header, side navigation, bottom navigation, comments, and article are all located. This lets it separate out things like “the outbound links in the sidebar” because they might be blogroll links.
But it’s even more detailed than that. ontolo identifies seven “Sections” and more than a dozen “Contexts” per section, and several different “Elements” (links, text, etc) per Context. This let’s the ontolo parser identify things like “the author’s name of the second comment” or “the publish time of the actual article” or “the RSS feed URL” or “the social media links in the footer.”
This kind of granularity, as far as I know, exists nowhere else. And because of how ontolo is so obsessively and meticulously designed, it’s able to do all of this at a rate of more than 4,000 web pages per second, while most “common” solutions like this one by moz is able to identify only the main content block at a rate of around 100 web pages per second.
To be clear, this isn’t a knock against moz. They’re solving a very different problem in a very different way. But this does demonstrate both the level of difficulty of the problem, along with speed improvement you get with ontolo vs. other marketing tools.
The Index
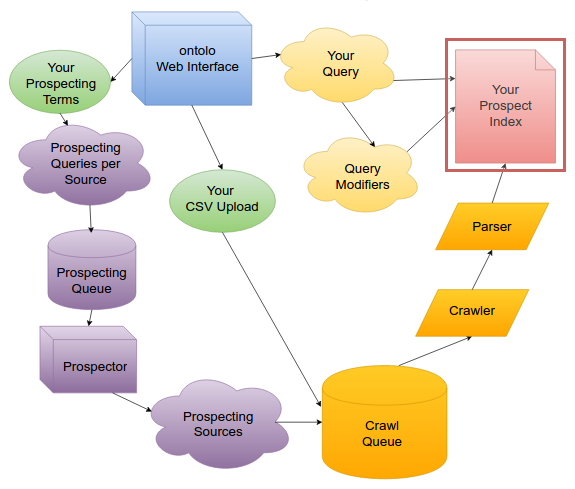
Once the Prospect has made it through the parser, and is now in tens of thousands of little pieces, neatly categorized, it’s time to send it to the search index.
This is pretty straightforward, but, for competitive reasons, I’m going to avoid discussing the details of how ontolo stores this data.
But I will say this: this is the piece of the puzzle that, if you get it wrong, the entire thing will never work. It took me almost 12 months to figure this piece out. And I’ve never seen the principle that allowed me to figure this out, discussed anywhere else. But it’s a tough one.
That said, the ontolo index is fast. Not only can you add a lot of documents to it very quickly and have them ready for you in a split second, but when you search on the entire set, it’s still very, very fast, almost always getting results back in under a quarter second, even when there are millions of documents in an index.
Querying
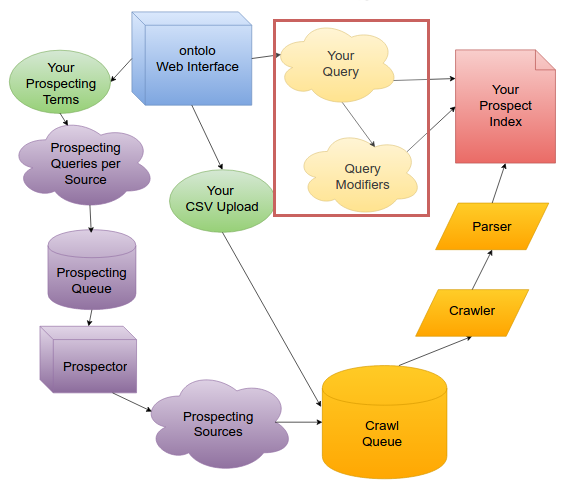
Now that you’ve added Prospects to your index, it’s time to let the querying tools filter them out. I’ve made the analogy before that ontolo is like casting a wide net AND going through it instantly with a fine-toothed comb. The querying process is the fine-toothed comb. Or, perhaps more precisely: each query is like lots of fine-toothed combs.
When you run a search on Google, you usually type in a few words, then get your results. You do the same with ontolo, but you’re able to specify with ontolo that you want results with Facebook users in links, or ads on the page, or even specific ads like Google AdSense, or contact pages, etc.
So ontolo gives you not only the ability to search by topic/term, but ALSO by marketing opportunity. And this is where the querying process comes into play.
I mentioned that there are 765 Prospecting Templates that ontolo uses. Well, the file containing all of the Query Templates for ontolo is over 4,000 lines long. And, even faster than the Prospecting Templates, this is rapidly growing in size as even more precision is folded into ontolo.
Query Results
This part of the process is why the most recent release was delayed an extra three weeks. And this is also another great example of where C simply outperforms other programming languages, flat out.
As I was getting ready to release this most recent version a month ago, I was on the last step: generating the results and reports.
The front-end of ontolo is written in PHP (I’d like to make a joke here about writing my own web server this year to replace Nginx and WordPress to get even more speed out of it, but that wouldn’t be a joke.) and I was having PHP handle the final step of results analysis.
I was about halfway through the report generation, but the processing was taking about six seconds. At that rate, it would have very possibly taken more than 10 seconds to fun the final analysis.
So, two weeks later, I had a post-processing server written from scratch that sits between the web server and the index. When you run a query, that query goes to an application I refer to as IDX, and IDX talks to the actual Index. IDX gets the results, then runs the analysis that gets you things like the Overview report. It then sends that data to the web server, which displays the results you see.
But instead of taking 10 seconds to do it, it averages completing the entire analysis in 0.15 seconds. And I have a new version I’m wrapping up that I expect could get it to 0.05 seconds or faster.
Today is the Last Day for the Discount on All Plans
If this is something you might be interested in, for this week only, we’re offering 10% off all plans, including yearly plans, which are already discounted 10%.
This Week’s Tutorials
I’m walking through various use cases this week. I’m guessing at least one, if not all, would be pretty useful for you. So be sure to read these each day this week.
Here’s the lineup:
- Monday: Content Marketing Research and Identifying Influencers
- Tuesday: Link Building
- Wednesday: Reputation Management Research
- Friday: Behind the Scenes of ontolo’s Technology
And that’s that.
I’m looking forward to helping you dramatically cut your research time so you can focus on the more creative parts of your campaigns.
I’ll see you on the other side.
– Ben